对于前端开发者而言,图片占位生成器是一个不可或缺的工具。
在实际开发中,我们经常会碰到这样的场景:产品展示页面的布局已经完成,各个模块都已就位,唯独缺少产品图片。而此时设计团队反馈:「图片素材还在制作中,预计下周交付。」
另一种常见情况是,在调试图片列表的响应式布局时,需要各种尺寸的测试图片。传统做法是通过搜索引擎寻找合适的图片,然后逐一下载、裁剪、调整尺寸。这个过程往往耗时良久,严重影响开发效率。
除了效率问题,版权风险也不容忽视。在项目中使用网络图片时,我们必须考虑:这些图片是否有版权限制?是否适合在商业项目中使用?这些问题如果处理不当,可能会给项目带来法律风险。
还有一些场景,如我们动态生成图片,在图片上显示提示的内容这种相对小众的场景。
本周刚好有一个需求是给飞书捷径做一个小功能用到了图片占位生成。梳理完需求,大概如下:
- 能指定宽和高
- 能自定义文字
- 能指定文本颜色和背景色
- 能指定图片格式输出,支持 PNG
- 能指定文本大小
- 能在飞书中使用
首先我们看一下有哪些在线的图片占位生成器可用的。
我们先让最新的 Claude-4-Opus 大模型给出 10 个地址,如下图:
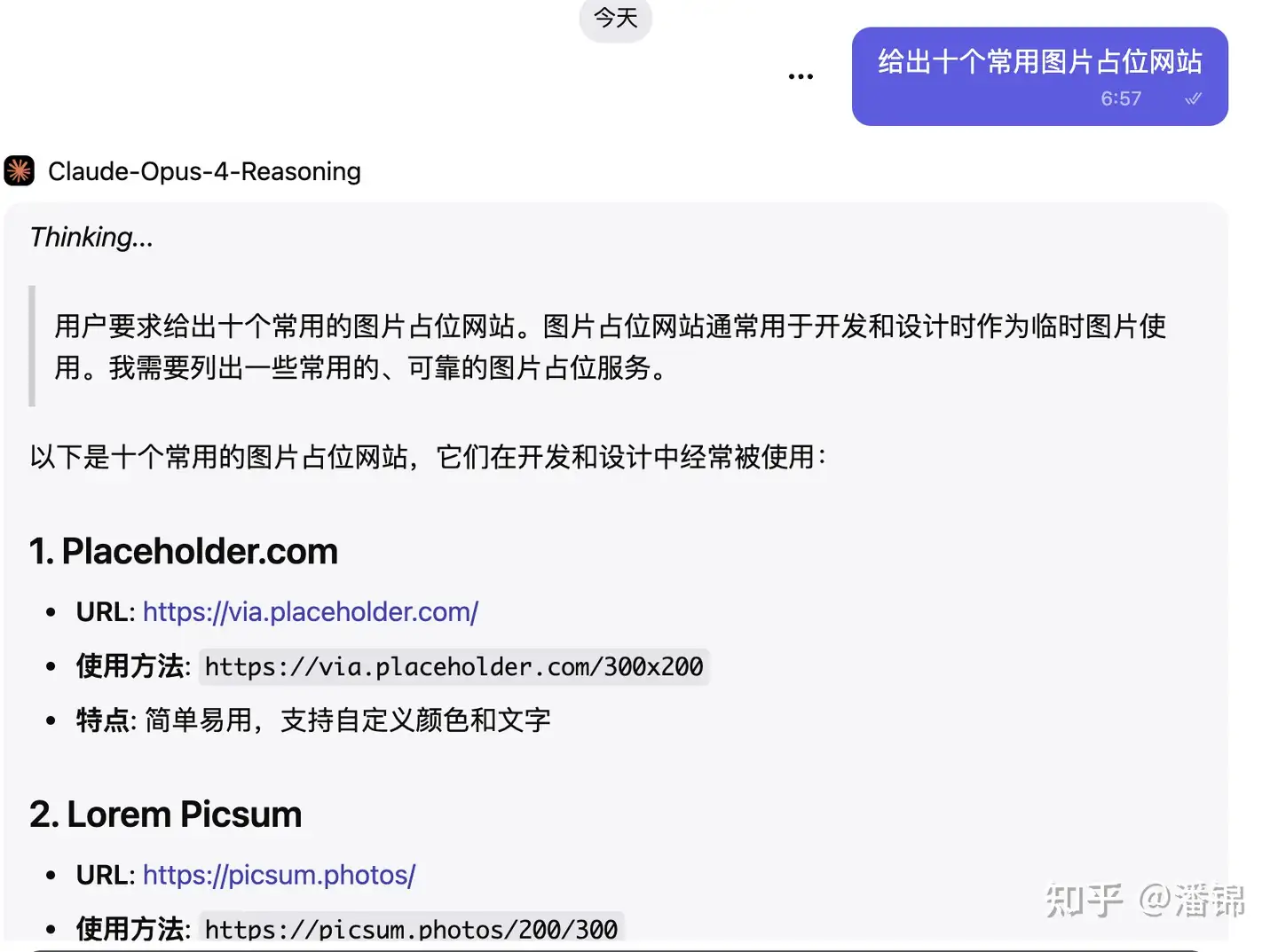
1. **Placeholder.com【不可用】**
- **URL**: https://via.placeholder.com/
- **使用方法**: `https://via.placeholder.com/300x200`
- **特点**: 简单易用,支持自定义颜色和文字
2. **Lorem Picsum【能用,随机真实图片】**
- **URL**: https://picsum.photos/
- **使用方法**: `https://picsum.photos/200/300`
- **特点**: 提供随机的高质量真实图片
3. **Placehold.it【跳到 Placeholder.com 也不可用了】**
- **URL**: https://placehold.it/
- **使用方法**: `https://placehold.it/350x150`
- **特点**: 经典的占位图服务,支持多种格式
4. **PlaceIMG【不可用】**
- **URL**: https://placeimg.com/
- **使用方法**: `https://placeimg.com/640/480/any`
- **特点**: 可选择不同类别(动物、建筑、自然等)
5. **Dummy Image【可用,不支持中文】**
- **URL**: https://dummyimage.com/
- **使用方法**: `https://dummyimage.com/600x400/000/fff`
- **特点**: 高度可定制,支持自定义背景色和文字颜色
6. **LoremFlickr【可用,不支持自定义内容】**
- **URL**: https://loremflickr.com/
- **使用方法**: `https://loremflickr.com/320/240`
- **特点**: 基于Flickr的真实图片,支持关键词搜索
7. **Placekitten【不可用】**
- **URL**: https://placekitten.com/
- **使用方法**: `https://placekitten.com/200/300`
- **特点**: 提供可爱的猫咪图片作为占位图
8. **Unsplash Source【不可用】**
- **URL**: https://source.unsplash.com/
- **使用方法**: `https://source.unsplash.com/1600x900/?nature`
- **特点**: 使用Unsplash的高质量图片库
9. **PlaceBear【可用,不支持自定义内容】**
- **URL**: https://placebear.com/
- **使用方法**: `https://placebear.com/200/300`
- **特点**: 提供熊的图片作为占位图
10. **FakeIMG.pl【可用,不支持中文】**
- **URL**: https://fakeimg.pl/
- **使用方法**: `https://fakeimg.pl/300x200/ff0000/ffffff?text=Hello`
- **特点**: 支持自定义文字、字体和颜色
以上 10 个站点看下来,就 1 和 5 相对符合需求,但都不支持中文。
AI 不行,搜索来凑,一顿 Goole 下来,又找到以下的几个:
1.http://placehold.co【可用,不支持中文】
示例:https://placehold.co/600×400?text=Hello+World

2.fakeimg.pl
示例:https://fakeimg.pl/300/?text=哈哈&font=noto

fakeimg.pl 在功能上需求都能满足,不管是大小、字体、中文,但是它在飞书中作为附件使用的时候竟然出错了。使用 dummyimage 却没有这个问题。 试了几次发现怎么都绕不过去,只能另想他法。
3.tool.lu
示例:https://iph.href.lu/600×400?text=哈哈哈

tool.lu 的图片占位功能能完全满足需求,但是和 2 一样,在飞书下会报错。
4.devtool.tech
界面最好的一个生成站点,但是格式是 SVG 的
以上只是基本可用的,还不排除那些功能不满足,失效了的,各种,折腾了两个小时,能满足需求的飞书用不了,飞书能用的不支持中文,死循环了。
只能自己撸了。
祭出 AI,花了两小时(代码只花了半小时,还包括框架搭建),本地运行没有问题,把代码部署到线上,能正常显示,但是飞书用不了,一样的报错:
execute error,捷径执行出错:
Error: execute原始执行结果:
捷径返回错误码: FieldCode.Success
转换结果:transform cell value fail
这回是自己写的代码,终于可以定位并解决问题了。对比能用的地址和不能用的地址,从头文件中发现了两个字段的差别,一个是跨域:Access-Control-Allow-Origin,一个是返回长度:Content-Length
最终试验发现是:Content-Length
可能飞书在获取图片并上传成附件的时候做了判断或者校验(就是个 BUG)。
这个功能已经作为免费的服务放到了开发哥网站(还记得之前 Vibe Coding 写的那个网站不):
https://www.kaifage.com/tools/placeholder

以上。
多说一句,即梦 3.0 生图中的汉字越来越精细了。