人生在世,如身处荆棘之中!心不动,人不妄动,不动则不伤。如心动,则人妄动,伤其身,痛其骨,于是体会到世间诸般痛苦。
选择在这个宜嫁娶、宜开光、宜安床的日子里,我们将第六章发布了。 没有华丽的出场,只有深夜的辗转,我们在努力。 虽然过程中有一些纷纷扰扰,但是经历了风雨的彩虹会更加美丽。
这次发布更新的主要内容有:
- 新增加第六章内存管理
- 增加CHM格式的支持
- 部分内容调整
TIPI团队
这次发布时我们提供了CHM版本的下载,
PHP的官方文档PHP type comparison tables 列出PHP类型和比较运算符在松散和严格比较时的作用。当阅读这篇说明时, 其中有一个NOTE:HTML 表单并不传递整数、浮点数或者布尔值,它们只传递字符串。 道出了我们WEB开发过程中数据交互的本质。 一如XML,JSON等等都是字符串,只是依照不同的需求制定规则,让人们能够更好的理解。 再看HTTP协议,不管是request还是response,最终的载体都是字符串,只是依照不同的字段和规则实现所需要的缓存优化、信息传递等功能。 有点扯远了,回到今天的主题,PHP的比较方式。
PHP的一些语言结构以及函数在默认实现上都是以松散比较的方式实现,如switch结构、array_keys、in_array、array_search等函数。 如果我们要使用严格的比较,对于switch语言结构本身并没有提供相关的实现,我们可以通过先将变量转换成对应的类型后再使用switch, 对于array_keys等函数,在PHP5以后都提供了$strict参数,将其设置为TRUE即可。 PHP的松散和严格比较表现最明显的是==和===。 我们从这两个语法结构来查看PHP对于松散和严格比较的实现。
从词法分析开始,在Zend/zend_language_scanner.l文件中我们找到==和===对应的token,如下:
<ST_IN_SCRIPTING>"===" { return T_IS_IDENTICAL; } <ST_IN_SCRIPTING>"==" { return T_IS_EQUAL; }
PHP在词法结构上将这两种方式进行彻底的区分,==对应T_IS_EQUAL标识,===对应T_IS_IDENTICAL标识, 如果我们在写程序的过程中同时使用了以上两种符号会出现什么呢?如下代码:
$num = 1; $str = "1"; if ($num === $str == $num) { echo 'phppan'; }
这里就不给出答案了(^_^)。
我们接着看语法解析,在Zend/zend_language_parse.y文件中我们可以看到如下代码:
| expr T_IS_IDENTICAL expr { zend_do_binary_op(ZEND_IS_IDENTICAL, &$$, &$1, &$3 TSRMLS_CC); } | expr T_IS_EQUAL expr { zend_do_binary_op(ZEND_IS_EQUAL, &$$, &$1, &$3 TSRMLS_CC); }
仅仅是通过上面的所给的代码,不去查看Zend/zend_complice.c中关于zend_do_binary_op函数的实现, 我们可以猜测出其最终会生成ZEND_IS_EQUAL和ZEND_IS_IDENTICAL中间代码。 最终所有的ZEND_IS_IDENTICAL中间代码对应的执行函数都会调用is_identical_function函数实现严格对比, 所有的ZEND_IS_EQUAL中间代码对应的执行函数都会调用compare_function函数实现松散对比。
compare_function函数的具体实现在Zend/zend_operators.c文件。 compare_function的比较过程是一个穷举遍历比较的过程,程序在实现过程中对于传入的两个变量做类型的识别, 以两个变量的类型对为key,如字符串与字符串比较,数组和数组比较,浮点型和整型的比较,构造的类型对如果顺序不同,其对应的处理也是不同的。 如下列表,为所有可直接识别的类型对:
除此之外,还有一些特殊的情况,如下代码:
$arr = array(1); $num = 1; if ($arr == $num) { echo 'yes'; }else{ echo 'no'; }
这些代码最终会输出no,但是在compare_function返回的结果为1。 他不属于上面所说的任一种类型对,由于第一个操作数为数组,则其走的程序流程分支为:
else if (Z_TYPE_P(op1)==IS_ARRAY) { ZVAL_LONG(result, 1); return SUCCESS; }
以上的代码将1赋值给result,但是在中间代码的执行函数中,执行完compare_function后会执行如下代码:
ZVAL_BOOL(result, (Z_LVAL_P(result) == 0));
因为比较的最终结果为真假,而在比较中除了0,其他的都是不等于。
如果是比较字符串和整数,则其最终都将字符串转化成数字(整数或浮点数)再进行比较,即最终比较的方法是可以识别的类型对之一。 如果是数组和数组的比较,由于存在数组与数组的对比,则其直接调用zend_compare_arrays完成比较。
与松散比较类似,严格比较也有一个对应的函数–is_identical_function。 同样,其实现也在Zend/zend_operator.c文件。 和loose comparison不同,strict comparison在严格意义上来说进行的不是一个纯粹的比较过程,它首先会判断两个变量所处的ZVAL容器的类型是否一样, 如果不一样直接返回0,即不相等。 如果两个ZVAL窗口的类型一样,则根据比较的第一个操作数的类型作区分,然后判断两个操作数的值是否一样, 这里之所以要分别对待每种类型,是因为在PHP中不同类型的值存储的位置不同,其对应的获取方法也不相同。
在看完了PHP关于松散比较和严格比较的源码,我们最后看一段代码,你觉得应该会输出什么?
$str = "0"; if (empty($str)) { echo 1; } $str = "00"; if (empty($str)) { echo 2; }
在维基百科中有这样一段描述: 凡是位于速度相差较大的两种硬件之间的,用于协调两者数据传输速度差异的结构,均可称之为Cache。 从最初始的处理器与内存间的Cache开始,都是为了让数据访问的速度适应CPU的处理速度, 其基于的原理是内存中“程序执行与数据访问的局域性行为”。
在处理器与物理内存间有三级缓存,如下图: 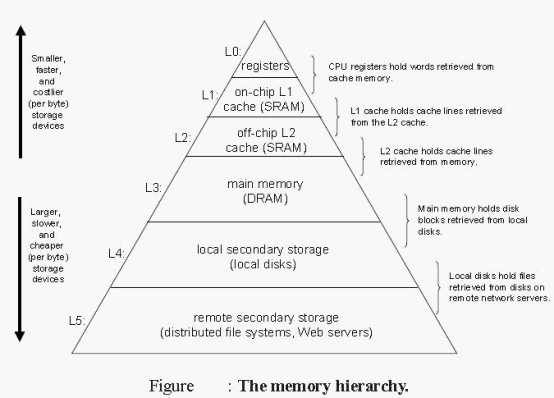
这是《深入理解计算机系统》上的一张图,对于每一层,位于上层的更快更小的存储设备作为位于下层更大更慢的存储设备的缓存。 从物理内存往上越往处理器方向走,存储设备的成本越高,并且更小,访问的速度更快。 它们是作为存储在更大更慢的存储设备的缓存而存在,它们的作用在于协调处理器与物理内存间的传输数据不一致。 但是把内存单独拉出来说,它也是一种缓存,它的作用也是为了将硬盘或其它较慢存储介质中的数据更快的提供给处理器。
DNS(域名解析系统)缓存是指当第一次访问某个站点的时候,客户端会向DNS服务器发出解析请求, 然后把信息保存在本机的DNS缓存以备再次访问。启用DNS缓存能提高网络访问速度,相应地,计算机的安全性降低了。
HTTP为提高性能,减少网络传输的信息量,从而使用了缓存。 HTTP协议缓存的目标是去除许多情况下对于发送请求的的需求和去除许多情况下发送完整请求的需求。 在HTTP协议中使用截止模型和证实模型来实现缓存。 协议它只是协议,只是一种通行的建议和规范,关键还是看客户端的实现。 比较直观的体现是:当第一次去一个网站时加载会比较慢,但再次打开这个网站时速度会快很多。 这是由于基于HTTP协议,浏览器客户端将一些CSS,图片等文件都缓存在本地,从而不再需要从服务器读取。
DNS缓存、HTTP协议缓存的作用与处理器缓存有一些不同,虽然也是协调数据传输速度的差异,但是其本质的差别是它已不再是纯粹的两种硬件之间的差异, 而是引入了网络的元素,换一种表示方式:凡是位于速度相差较大的两种实体之间的,用于协调两者数据传输速度差异的结构,均可称之为Cache。
这里没有用数据库缓存是因为数据库与数据库系统在概念上不是一回事。数据库是“按照数据结构来组织、存储和管理数据的仓库”。 而数据库系统是一个实际可运行的存储、维护和应用系统提供数据的软件系统,是存储介质、处理对象和管理系统的集合体。 我们平时所说的数据库缓存是数据库系统所提供的缓存功能。
以MySQL为例,我们使用最多的是查询缓存(Query Cache)。 它的实现过程不是很复杂,当客户端请求了一个查询后,MySQL通过特定的Hash算法生成一个标识用的hash值, 得MySQL计算完后,返回的结果集将与这个生成的hash值对应存放在内存中。若此缓存没有过期时, 下一次相同的请求过来时将直接返回结果,不再需要SQL解析,计算等操作。
PHP内存管理中的缓存也是基于“程序执行与数据访问的局域性行为”的原理。 引入缓存,就是为了减少小块内存块的查询次数,为最近访问的数据提供更快的访问方式。 其实现过程主要包括以下的一些活动:
此处的文件缓存是指在应用开发过程中将一些中间结果存放在文件,以备下次使用。 如在PHP中一些模板系统的实现,以其规则编写了模板文件,生成中间的PHP文件,如果用户调用某个页面则直接访问PHP页面,而跳过了模板的解析过程
以上三种缓存与前面也不一样,它实际上是将一些需要计算后的结果缓存,下次直接返回计算后的结果。依此,则缓存的表述可以再次修改为: 凡是获取数据速度相差较大的两种实体之间的,用于协调两者数据传输速度差异的结构,均可称之为Cache。